1. CNN
CNN - 이미지를 기반으로 한 영상처리에서 우수한 성능을 보이는 신경망
영상처리 : 디지털 이미지의 조작, 분석, 인식, 생성등의 목적을 달성하기 위한 기술
1) 합성곱 연산
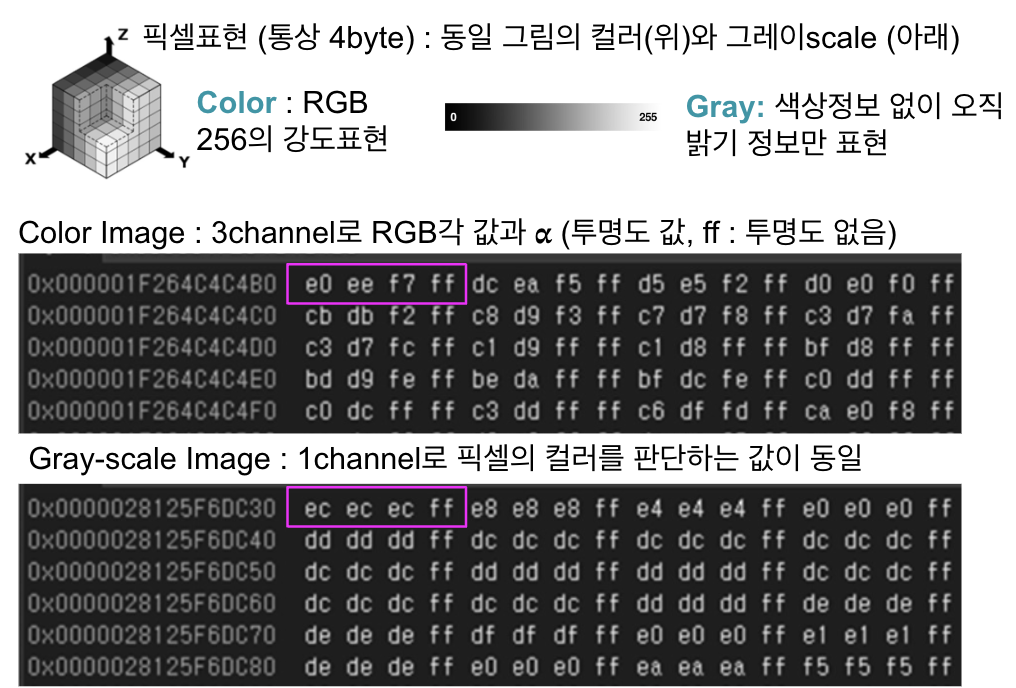
(1) 영상의 표현 : RGB(그레이의 경우 값이 같음)와 투명도 값으로 표현
(2) 합성곱 연산(필터링 연산)
- 하나의 함수와 또 다른 함수를 반전 이동한 값을 곱하고 구간에 대해 적분하여 새로운 함수를 구한 연산자
가중합 ( Σ 𝝎ᵢ𝒙ᵢ + 𝑏 )의 기본식, 𝝎ᵢ의 값(합성곱 필터의 픽셀값)곱하여 더하여 구간의 값을 구함
(합성곱의 경우 필터를 적용하는 것이 가중치 적용, 더하는 것이 적분)
- 합성곱 신경망은 학습을 통해 가중치를 결정 (학습 완료전까지 필터 가중치 파악할수 없음)
예) 포토샵, 사진 어플리케이션의 필터 기능 (이미지에 서로 다른 고정된 가중치, 윤곽/블러/Sharpen,/엠바스)

(3) 합성곱 연산의 사용사례
① 객체 구분
- 분류 : 이미지 내 하나의 객체가 존재할때 하나의 범주로 구분
- 분류+지역화 : 하나의 객체를 구분하고 위치정보를 출력
- 객체 감지 : 이미지 안에 여러개의 객체가 존재, 객체의 존재여부 및 위치정보 출력
- 인스턴스 분할 : 이미지 내 픽셀 수준에서 객체의 형상에 따라 영역표시
같은 범주여도 서로 다른객체로 구분 (dog1, dog2,cat 1)

② 픽셀 복원 : 이미지를 저해상도 변환후 이미지가 무엇과 유사한 형태를 보이는지 예측
③ 색복원 : 흑백의 영상을 색이 있는 영상으로 변경
(4) 합성곱 연산의 필터
- 이미지에 효과를 주는 기존의 필터는 고정된 필터로 처리
- 합성곱 신경망에서는 고정필터 사용하지 않으며, 입력 데이터를 이용한 학습과정을 통해 가중치결정
2) 합성곱 신경망
(1) 합성곱 신경망
- 입력데이터의 공간적인 특징을 추출하는데 특화되어 정보 손실이 적음 (인접 픽셀을 모두 이용한 연산)
- 필터 가중치 공유와 풀링층을 통한 데이터 크기 축소로 인해 연산이 효율적
( MLP는 1차원 배열로 만든후 신경망의 입력 후 가중치 계산으로 정보 손실이 큼 )
- 입력층, 합성곱층, 풀링층, 완전연결층으로 구성
(2) 입력층
- 데이터가 CNN에서 처리될수 있도록 변환, 높이/너비/채널(3차원)의 값으로 구성
- 컬러(RGB)는 3개의 채널, 단색(gray-scale)은 1개의 채널, (높이,너비,채널수)로 표현
(3) 합성곱층
- CNN에서 가장 많은 연산처리, 이전층에서 입력받은 데이터와 필터(커널)을 통해 연산
- 필터의 크기는 3x3, 5x5, 7x7등 홀수로 구성
- Feature Map 구성 ( 종류가 다른 여러개의 필터적용시 필터별 특징맵 )
① 합성곱 연산
- 각 픽셀의 값과 필터의 곱을 더하여 특징맵 추출
- 특징맵의 갯수는 적용되는 필터의 갯수에 따라 달라짐 (같은 필터 적용시 합하여 결과값)


② Stride
- 합성곱 연산 후 왼쪽에서 오른쪽으로 이동하며 연산 진행시 이동 간격(조절가능)
- 합성곱 연산결과인 특징맵의 크기는 필터크기와 스트라이드에 의해 결정됨
③ 패딩
- 임의의 데이터 주변을 가상의 값으로 채움, 모서리에 중요한 특징이 있는 경우 정밀하게 추출
- 합성곱 연산 후 출력 데이터를 입력데이터와 같게 유지가능
- 특징맵의 크기 = (입력데이터 - 필터크기 + 2*패딩값)/스트라이드 + 1

- 합성곱층 구현 (keras.layers의 Conv2D함수)
tf.keras.layers.Conv2D(filters,kernel_size, trides=(1,1),padding='valid',activation="None")
filters : 필터의 갯수,
kernel_size : 필터(커널)의 크기
strides : 필너가 움직이는 간격의 크기, 기본값 =(1,1)
padding : 가상의 값으로 채우는 것, valid(패딩없음)/same(입/출력 데이터크기를 동일하게)사용
activation : 사용할 활성함수 (기본값 : None)
- Activation Function

(3) pooling layer
- convolution layer의 output을 받아서 크기 축소 (down sampling, sub sampling)
- 데이터의 크기가 작아지므로 연산량 감소 ( 합성곱과 달리 학습을 위한 가중치 없는 단순 축소)
채널수 변하지 않음 (입력된 채널대로 출력) , 입력데이터가 일부 변경시 풀링의 결과는 크게 변화X
- 특정 영역의 최대 혹은 평균을 취하는 과정
① max-pooling ( 특성을 그대로 가져오며 연산이 간단하여 보편적 사용 )
② average-pooling ( 별도의 연산이 추가되며, 특성값도 변경될 가능성 있음 )
- Feature Map의 크기 = (입력데이터 크기-풀링크기)/stride + 1

- 풀링층 구현
keras.layers의 MaxPooling2D or AveragePooling2D
pool_size, strides(default : 2x2, none)
예) tf.keras.layers.MaxPooling2D (pool_size=(2,2), strides=None)
** strides = None인 경우
(4) 완전연결층 (Fully Connected Layers)
- 한층과 다음층이 모두 연결된 상태, 다층퍼셉트론(MLP)을 지칭하는 또 다른 용어
- Softmax : 출력층의 활성함수, 다중 클래스 분류모델의 출력의 총합을 1로 하는 함수
(클래스 확률을 0~1로 정규화)
- Flatten Layer : flatten함수()로 구현, 매개변수 없음
Dense층 : tf.keras.layers.Dense()함수의 unit(출력뉴런 수), activation설정(활성함수)
- 완전연결층 구현 (keras.layers의 Flatten, Dense함수)
예) tf.keras.layers.Flatten(data_format=None)
tf.keras.layers.Dense(units, activation=None)
2. 합성곱 신경망의 구현
합성곱 신경망의 기본구조 : 입력층 - 합성곱층 - 풀링층 - 완전연결층

1) 합성곱 신경망의 구현
관련 패키지 호출 및 데이터 준비 - 모델 및 학습
(1) 관련 패키지 호출
- TensorFlow, Keras, Fashion MNIST, Numpy, Matplotlib

(2) 데이터 준비 및 확인



(3) 모델 생성 및 학습
데이터 정규화 - 모델생성 (keras.Sequential) - 학습 - 학습 정보조회 - 함수평가
① 데이터 정규화 : 이미지 색상 범위 0~255, 데이터 값 0 ~ 1 정규화
② 모델 생성 (keras.Sequential) : 모델 객체를 생성, 모델을 구성하는 레이어를 리스트 형태로 전달
③ 학습하기
- model.compile()을 사용하여 모델 컴파일
- model.fit()은 모델을 학습하기 위한 함수
- 손실 함수 ( 별도로 원핫인코딩 하지 않음 )
sparse_categorical_crossentropy : 10개의 레이블 40byte ( 정수형, 4byte * 10 )
categorical_crossentropy : one-hot-encoding변환부담과 메모리 소요 (4byte*10*10)


④ 함수정보 구현함수(내용확인)
- history객체는 학습과정의 손실과 정확도 등의 정보를 포함, plot_loss()는 history라는 매개변수를 받음

⑤ 성능 평가함수 구현 및 확인하기
- 새로운 데이터에 대한 일반화 정도를 파악하기 위해 테스트 데이터셋을 이용하여 평가(정확도 출력)

3. LeNet 5
- Yann Lecun(얀르쿤)연구팀이 1988년 손글씨 이미지를 분류하기 위해 개발한 합성곱 신경망
- LeNet-1, LeNet-4, Boosted LeNet-4등 ( 여러개 분류기를 사용하는 앙상블, Boost)다양한 버전
- 앙상블 : Boost (가중치로 최적값 산출 ), Bagging ( 평균기반 )

1) LeNet-5모델의 구성
- 3개의 합성곱(Convolution)과 2개의 샘플링(Sampling), 완전연결층을 통해 분류수행
Input→ C1(Conv)→ S2(Pooling)→ C3(Conv)→ S4(Pooling)→ C5(Conv)→ F6(완전연결)→ 출력

(1) Input
- MNIST 데이터셋 : 60,000개 트레이닝 세트 & 10,000개 테스트 세트
- 레이블(0~9), 픽셀 크기 (28*28)
- 입력 특징 : 32*32의 중앙에 위치하도록 패딩 처리 (정밀한 특징 추출)
(2) C1 : 5x5 filter 6개, stride 1, activation function : tanh, 32X32입력, 연산후 28x28x6
(3) S2 : 2x2 평균 Pooling, stride 2, Subsampling(학습X, 가중치X) 연산후 14x14x6
(4) C3 : 5x5 filter 16개, stride 1, activation function : tanh, 연산후 10x10x16개의 특징맵
- 16개의 특징맵을 얻기 위해 중복되지 않도록 특정 필터 입력만 활용(특징맵의 연결 제한, 연산량 감소)
- 서로 다른 입력값으로 각 특징맵은 서로다른 특징을 상호보완적으로 추출
예) 0번째 특징맵을 얻기 위해 0, 1, 2번의 입력만 활용하여 계산

(5) S4 : 2x2 평균 Pooling, stride 2, Subsampling(학습X, 가중치X) 연산후 5x5X16
(6) C5 : 5x5 filter 120개 (각 필터는 16*5*5를 통 연산하여 하나의 특징맵의 특징 정보를 추출)
stride 1, activation function tanh, 연산후 1x1x120 (스칼라값)
(7) F6 : 120개의 1x1 feature map을 84개의 unit에 연결, 출력은 (84,)
(8) Output : 84개 Unit을 activation function RBF(Radial Basis Function), 10개 unit으로 출력
10개의 출력으로 레이블 출력
① RBF (가우시안 연결, 방사형 기저함수) : 입력값과 가중치 사이의 거리에 기반하여 값을 계산하는 함수
비선형 방정식 근사, 고차원 입력데이터 저차원 공간에 사상사용
- Hidden Layer 1개(MLP보다 학습빠름), 선형출력층(가중치 계산용이), 입력- 은닉층(가중치 없음)
- 유클리드 거리 ( 맨하탄 거리 L1 norm , 유클리드 거리 L2 norm )

2) LeNet-5의 구현
입력층 - 합성곱층 - 풀링층 - 합성곱층 - 풀링층 - 합성곱층 - 완전연결층 - 출력층

1) 합성곱 신경망의 구현
관련 패키지 호출 및 데이터 준비 - 모델 및 학습
(1) 관련 패키지 호출
- tensorflow/keras, jeras.dataset/mnist, keras.models/Sequential
- keras.layers/Conv2D, MaxPooling2D, Dense,Flatten, Layer
- keras/backend, Numpy
(2) 데이터 준비 및 확인
- mnist.load_data()로 mnist데이터 셋호출
- x_train , x_test는 이미지 데이터이며, y_train, y_test는 레이블 (범주)데이터



(3) 모델 생성 및 학습
패딩처리 - 데이터 정규화 - 모델생성 (keras.Sequential) - 학습 - 학습 정보조회 - 함수평가
① 패딩 : 4개 차원으로 설정 ( 차원크기, 이미지 높이(상하), 이미지의 너비(좌후), 채널 수)
(0,0): 배치 크기 (즉 이미지의 개수), 배치 크기에 대해 패딩을 추가X (이미지의 수는 변하지 않음)
(2,2): 상하(이미지의 높이) 패딩, 위쪽에 2개의 픽셀, 아래쪽에도 2개의 픽셀을 추가
(2,2): 좌우(이미지의 너비) 패딩, 왼쪽에 2개의 픽셀, 오른쪽에도 2개의 픽셀을 추가
(0,0): 채널 수(흑백 이미지 1, 컬러 이미지 3), 채널에 대해서는 패딩을 추가X
② 데이터 정규화 : 이미지 색상 범위 0~255, 데이터 값 0 ~ 1 정규화 (경사소실 문제 일부해결)
③ 레이블 데이터 벡터화 : 정수 형태의 레이블
- 첫번째 인자는 데이터셋의 레이블, 두번째 인자는 범주의 갯수
- keras.utils.to_categorical()함수 , sparse_categorical_crossentropy
④ 모델 생성 : Sequential() 생성 후 여러개의 layer를 model.add()함수로서 차례로 추가하여 모델구성
⑤ 모델 학습 : 모델 객체를 생성, 모델을 구성하는 레이어를 리스트 형태로 전달
학습하기
- model.compile()을 사용하여 모델 컴파일
- model.fit()은 모델을 학습하기 위한 함수
- 손실 함수 : mean_square_error함수를 사용


'스터디 > Deep Learn' 카테고리의 다른 글
| 6. AutoEncoder & GAN , RNN (0) | 2024.09.29 |
|---|---|
| 5. Deep CNN (0) | 2024.09.27 |
| 3. 프레임 워크와 학습 기술 (0) | 2024.09.25 |
| 2. MLP (0) | 2024.09.23 |
| 1. 인공신경망과 퍼셉트론 (0) | 2024.08.31 |